Exploración de Datos Macroeconómicos con RStudio

Contenido
Descripción
1. Esperanza de vida
2. Producto interior bruto percápita
3. Paqueterías
4. Esperanza de vida y crecimiento económico
5. Gráfico de dispersión
6. Gráfico dinámico
7. Gráfico de datos suavizados algorítmo loess
8. Diagramas interactivos de caja
9. Gráfica con suavizamiento GAM
10. Curva de Preston
11. Exploración de datos macroeconómicos
12. Construcción de mapa
1. Esperanza de vida
2. Producto interior bruto percápita
3. Paqueterías
4. Esperanza de vida y crecimiento económico
5. Gráfico de dispersión
6. Gráfico dinámico
7. Gráfico de datos suavizados algorítmo loess
8. Diagramas interactivos de caja
9. Gráfica con suavizamiento GAM
10. Curva de Preston
11. Exploración de datos macroeconómicos
12. Construcción de mapa
Descripción
En el entrenamiento se visualizará el contenido del paquete Gapminder, en especial los datos globales de la esperanza de vida al nacer y del Producto Interno Bruto per Cápita. Igualmente se elaborarán gráficos interactivos, de tendencia y dispersión. Por último, algunas pruebas lineales para determinar correlación y comentarios de las principales observaciones.
La segunda parte del entrenamiento se hará con el paquete Quandl, una herramienta poderosa para descargar directamente información macroeconómica, en este caso de Venezuela, utilizando la plataforma del Banco Mundial y su base de datos llamada Indicadores del desarrollo mundial (WDI) "World Development Indicators".
Para concluir, se va ha construir un mapa interactivo para acceder a los datos macroeconómicos a través de Quandl con leaflet, lo que permite al usuario elegir un indicador económico y hacer clic en un país para acceder a los valores de ese indicador, campo de estudio de la Estadística Espacial.
1. Esperanza de Vida
La esperanza [1] de vida es una estimación del número promedio de años adicionales que una persona de una edad determinada puede esperar vivir.
La medida más común de la esperanza de vida es la esperanza de vida al nacer. Es una medida hipotética. Se supone que las tasas de mortalidad específicas por edad para el año en cuestión se aplicarán durante toda la vida de las personas nacidas en ese año.
La estimación, en efecto, proyecta las tasas de mortalidad (muerte) específicas por edad para un período determinado durante toda la vida de la población nacido (o vivo) durante ese tiempo.
2. Producto Interior Bruto (PIB) per Cápita
El producto interno bruto ( PIB ) per cápita es una métrica que desglosa la producción económica de un país por persona y se calcula dividiendo el PIB de un país por su población.
- El PIB per cápita es una medida global para medir la prosperidad de las naciones y es utilizado por analistas, junto con el PIB, para analizar la prosperidad de un país en función de su crecimiento económico.
- Los países pequeños y ricos y los países industrializados más desarrollados tienden a tener el PIB per cápita más alto.
En el entrenamiento se observará si existe alguna relación entre ambas variables: PIB per Cápita y Esperanza de Vida al Nacer agrupando los grupos por continentes y luego por países.
3. Paqueterías
Plotly
Para crear gráficos web interactivos a partir de gráficos ‘ggplot2’ y / o una interfaz personalizada de la biblioteca JavaScript, ‘plotly.js’ está inspirado en la gramática de los gráficos.
Gganimate
Para extender la API ‘ggplot2’ con gráficos animados, este paquete proporciona un conjunto completamente nuevo de gramática, totalmente compatible, para especificar transiciones y animaciones de una manera flexible y extensible.
Ggplot2
Sistema para crear gráficos declarativamente, basado en "La gramática de los gráficos ’‘. Se proporcionan los datos, se indica a ’ggplot2’ cómo mapear variables y su decoración.
GapMinder
Un extracto de los datos disponibles en Gapminder.org. Para cada uno de los 142 países del conjunto, el paquete proporciona valores para la esperanza de vida, el PIB per cápita, y población, cada cinco años, de 1952 a 2007.
Quandl
Funciones para interactuar directamente con la API de Quandl y ofrecer datos en varios formatos utilizables en R, descargar un archivo zip con todos los datos de una base de datos de Quandl y la capacidad de buscarlos.
knitr
Proporciona una herramienta de uso general para la generación dinámica de informes en R utilizando técnicas de programación literaria.
kableExtra
Crea tablas HTML o ‘LaTeX’ complejas utilizando ‘kable ()’ de ‘knitr’ y la sintaxis de tuberías de ‘magrittr’. Este paquete simplifica la forma de manipular los códigos HTML o ‘LaTeX’ generados por ‘kable ()’ y permite usarlos para construir tablas complejas y personalizar estilos usando un formato de sintaxis legible.
Purrr
Es una programación funcional completa y consistente. Kit de herramientas para R.
Dygraphs
Una interfaz R para la biblioteca de gráficos JavaScript ‘dygraphs’ (una copia la cual está incluida en el paquete). Proporciona instalaciones ricas para graficar datos de series temporales en R, incluidos los altamente configurables, la visualización en serie, eje y características interactivas.
Rnaturalearth
Facilita el mapeo al hacer que los datos del mapa de la tierra natural de http://www.naturalearthdata.com/ estén fácilmente disponibles para los usuarios de R.
Sp
Clases y métodos para datos espaciales; el documento de clases donde se encuentra la información de ubicación espacial, para datos 2D o 3D. Se proporcionan funciones de utilidad, p. para trazar datos como mapas, selección espacial, así como métodos para recuperación de coordenadas, para subconjuntos, impresión, resumen, etc.
Rgeos
Interfaz con el motor de geometría: código abierto (‘GEOS’) utilizando la ‘API C’ para operaciones de topología en geometrías.
Leaflet
Crea y personaliza mapas interactivos usando el ‘Folleto’ Biblioteca de JavaScript y el paquete ‘htmlwidgets’. Estos mapas se pueden usar directamente desde la consola R, desde ‘RStudio’, en aplicaciones Shiny y documentos R Markdown.
Coefplot
Traza los coeficientes de los objetos del modelo. Esto muestra rápidamente al usuario las estimaciones puntuales y los intervalos de confianza para los modelos ajustados.
Ggrepel
Proporciona texto y etiquetas geoms para ‘ggplot2’ que ayudan a evitar etiquetas de texto superpuestas. Las etiquetas se repelen entre sí y lejos del punto de datos.
Socviz
Materiales de apoyo sobre visualización de datos. Contiene funciones de utilidad para gráficos y varios conjuntos de datos de muestra.
4. Esperanza de vida y crecimiento económico
El Producto Interno Bruto (PIB) es el valor de mercado de los bienes y servicios finales producidos en un país durante un período determinado. El PIB se usa comúnmente para indicar el bienestar económico de un país. El crecimiento a largo plazo del PIB de un país a menudo se asocia con un mejor nivel de vida. El país con mayor PIB tiene acceso a abundantes recursos y puede asignar gastos adicionales en el sector de la salud. Por lo tanto, a menudo se percibe que el PIB de un país debería tener un impacto directo en la esperanza de vida de sus ciudadanos.
El crecimiento económico a veces se estima dividiendo el PIB por el tamaño de la población. De esta manera, intenta capturar el crecimiento y el bienestar de una vez.
No obstante, se debe diferenciar claramente entre crecimiento y bienestar (así como crecimiento y desarrollo), el PIB per Cápita es una medida inadecuada como indicador de bienestar.
Se supone que el PIB se distribuye en partes iguales a cada miembro de la sociedad.
Por lo tanto, es más acertado multiplicar una medida del ingreso promedio por una medida de desigualdad, es decir, al peso de acuerdo con la cantidad de la población que realmente tiene una participación en el PIB.
5. Gráficos de Dispersión: Esperanza de Vida y Producto Interno Bruto per Cápita
Primero se preparan los paquetes y se instalan. Luego, utilizando la base de datos de Gapminder se realiza el primer gráfico. Muestra la panorámica de dispersión de dos variables macroeconómicas para el año 2007: La Esperanza de Vida al nacer y el PIB per Cápita. En el eje de coordenadas (Y) se encuentra los valores de la Esperanza de Vida al Nacer, en las abscisas (X) los valores del Producto Interno Bruto per Cápita, el tamaño de las burbujas viene determinado por el tamaño de la Población del país. Este tipo de gráficos es de 3 dimensiones.
library(plotly)
library(gganimate)
library(ggplot2)
library(gapminder)
library(Quandl)
library(knitr)
library(kableExtra)
library(purrr)
library(dygraphs)
library(rnaturalearth)
library(sp)
library(rgeos)
library(leaflet)
library(coefplot)
library(ggrepel)
library(socviz)gdata <- gapminder[gapminder$year==2007, ]
g <- ggplot(gdata, aes(x=gdpPercap, y=lifeExp, label=country)) +
geom_point(aes(col=continent, size=pop/1e6)) +
geom_text_repel(size=2, box.padding = unit(0.5, "lines"), force=1,
segment.size = .1, segment.color = 'grey', max.iter = 100) +
scale_x_log10() +
theme_classic()
g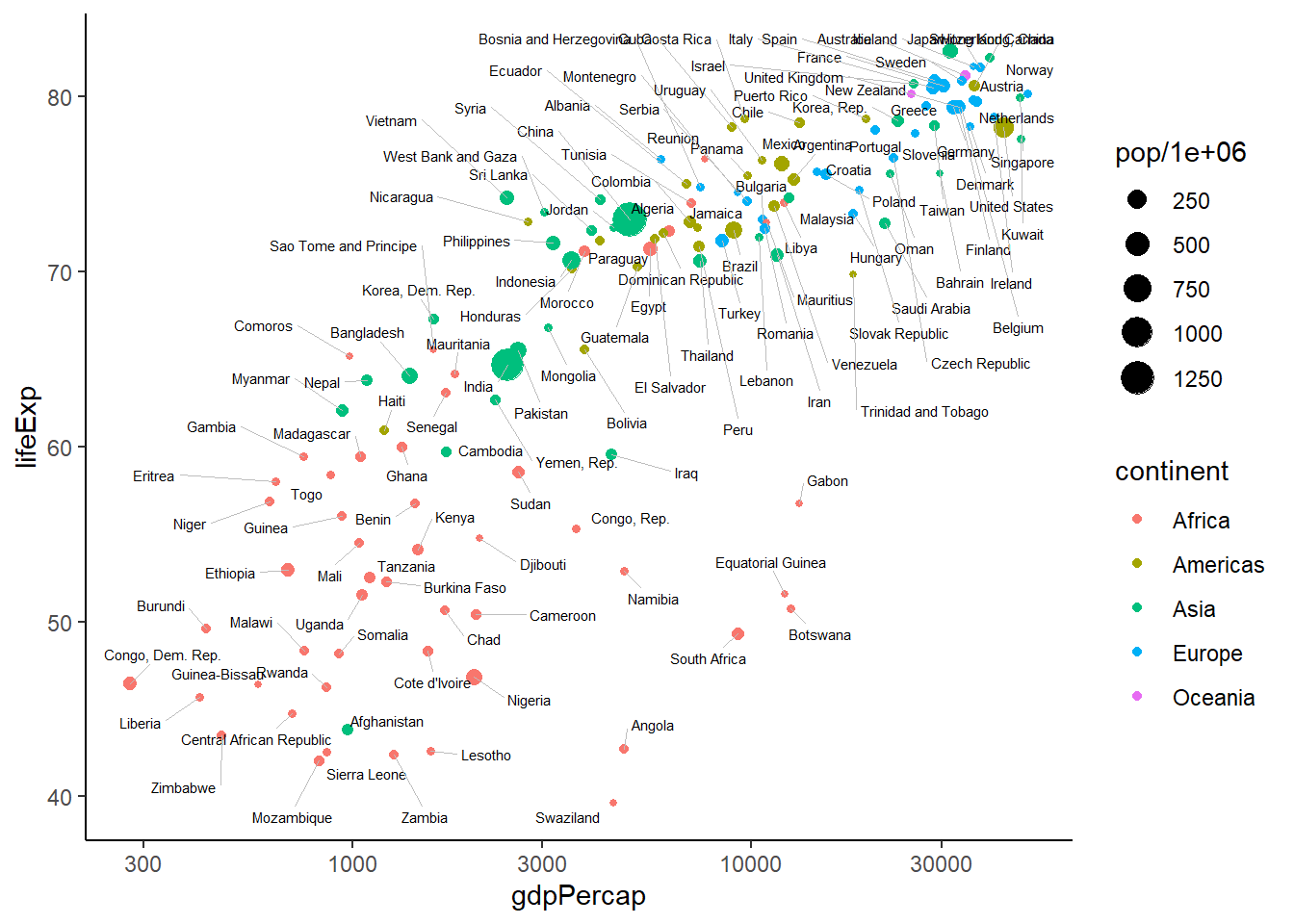
6. Gráfico dinámico
El gráfico muestra una animación del comportamiento de las variables en estudio agregando la temporalidad. Desde 1952 hasta 2007, los datos se actualizaron cada 5 años.
df <- gapminder
fig <- df %>%
plot_ly(
x = ~gdpPercap,
y = ~lifeExp,
size = ~pop,
color = ~continent,
frame = ~year,
text = ~country,
hoverinfo = "text",
type = 'scatter',
mode = 'markers'
)
fig <- fig %>% layout(
xaxis = list(
type = "log"
)
)
figGráfico interactivo
El gráfico permite interactuar con las variables y seleccionar un país para visualizar los valores completos: Esperanza de Vida, PIB per Cápita y Población.
ggplotly(p <- ggplot(
gapminder,
aes(x = gdpPercap, y=lifeExp, size = pop, colour = country)
) +
geom_point(show.legend = FALSE, alpha = 0.7) +
scale_color_viridis_d() +
scale_size(range = c(2, 12)) +
scale_x_log10() +
labs(x = "PIB per Cápita", y = "Esperanza de vida",title = "Experanza de Vida y PIB per Cápita"))Tablas de datos
Elaboración de tablas para visualizar los datos ordenados.
kable(aggregate(lifeExp ~ continent, gapminder, median), digits = 2, format = "html", row.names = TRUE) %>%
kable_styling(bootstrap_options = c("striped"),
full_width = T,
font_size = 15) %>%
scroll_box(height = "200px")| continent | lifeExp | |
|---|---|---|
| 1 | Africa | 47.79 |
| 2 | Americas | 67.05 |
| 3 | Asia | 61.79 |
| 4 | Europe | 72.24 |
| 5 | Oceania | 73.66 |
library("dplyr")
kable(gapminder %>%
filter(year == 2007) %>%
group_by(continent) %>%
summarise(lifeExp = median(lifeExp)), digits = 2, format = "html", row.names = TRUE) %>%
kable_styling(bootstrap_options = c("striped"),
full_width = T,
font_size = 15) %>%
scroll_box(height = "200px")| continent | lifeExp | |
|---|---|---|
| 1 | Africa | 52.93 |
| 2 | Americas | 72.90 |
| 3 | Asia | 72.40 |
| 4 | Europe | 78.61 |
| 5 | Oceania | 80.72 |
7. Gráfico de datos suavizado utilizando el Algoritmo Loess
El método utiliza una función de ponderación que hace que la influencia de los valores vecinos en el suavizado en una posición disminuya con la distancia a esta posición.
Los valores atípicos se ponderan menos que con otros métodos. El factor decisivo es la elección del ancho de suavizado, que refleja el número de valores que se incluyen en el cálculo de un punto. Ayuda a detectar la relación entre variables, encontrar tendencias y ciclos en los datos.
p <- ggplot(data = gapminder, aes(x = gdpPercap, y = lifeExp, color = continent))
ggplotly(p + geom_point() + geom_smooth(method = "loess") + scale_x_log10()+labs(
x = "PIB per Cápita",
y = "Experanza de Vida",
title = "Experanza de Vida y PIB per Cápita"
)) Suavizamiento de datos agrupándolos por continentes
p <- ggplot(gapminder, aes(x = year, y = gdpPercap))
ggplotly(p + geom_line(color = "gray70", aes(group = country)) + geom_smooth(size = 1.1, method = "loess", se = FALSE) + scale_y_log10(labels = scales::dollar) + facet_wrap(~ continent, ncol = 5) + labs(
x = "Año",
y = "PIB per cápita",
title = "PIB per cápita en los continentes"
))8. Diagramas interactivos de caja
Los diagramas de caja son un tipo de gráfico que da información visual sobre cómo se distribuyen los valores en los datos. Los diagramas de caja son una forma estandarizada de mostrar la distribución de datos basada en un resumen de cinco indicadores:
- Mínimo
- 1er Cuartil
- Mediana
- 3er Cuartil
- Máximo
library("ggplot2")
ggplotly(ggplot(gapminder, aes(x = continent, y = lifeExp)) +
geom_boxplot(outlier.colour = "hotpink") +
geom_jitter(position = position_jitter(width = 0.1, height = 0), alpha = 1/4)+labs(
x = "Continentes", y = "Esperanza de Vida en Años", title = "Gráficos de caja", caption = "Fuente: gapminder."
))9. Gráfica con suavizamiento GAM
Un modelo aditivo generalizado (GAM) es un modelo lineal generalizado (GLM) en el que el predictor lineal es dado por una suma especificada por el usuario de funciones suaves de las covariables más un componente paramétrico convencional del predictor lineal.
Permite observar el comportamiento del conjunto de datos ordenados con respecto a línea para “visualmente” inferir si existe algún tipo de orden o correlación.
p <- ggplot(data = gapminder, aes(x = gdpPercap, y = lifeExp))
ggplotly(p + geom_point(alpha = 0.3) + geom_smooth(method = "gam") + scale_x_log10(labels = scales::dollar) + labs(
x = "PIB per capita", y = "Esperanza de Vida en Años", title = "Crecimiento Económico y Esperanza de Vida", subtitle = "Los puntos de datos son años-país", caption = "Fuente: gapminder."
))10. La Curva de Preston
En 1975, Samuel Preston publicó un artículo influyente, “La relación cambiante entre la mortalidad y el nivel de desarrollo económico”, en el que traza la relación global entre el PIB per cápita y la esperanza de vida en diferentes momentos. Él encuentra que con el tiempo la curva que describe la relación se ha movido hacia arriba, lo que implica que un nivel de ingresos similar se asocia con una mayor esperanza de vida en momentos posteriores.
p <- ggplot(data = gapminder, aes(x = gdpPercap, y = lifeExp))
ggplotly(p + geom_point() + geom_smooth(method = "gam",formula=y ~ s(x, bs = "cs"))+labs(
x = "PIB per cápita", y = "Esperanza de Vida en Años", title = "Curva de Preston", caption = "Fuente: gapminder."
))Consideraciones
1.- Las correlaciones no implican causalidad.
2.- No se puede evaluar si el PIB per Cápita tiene un efecto causal en la esperanza de vida mediante un análisis simplista como el que se presenta aquí y la curva de Preston que presenta una considerable correlación puede ser fácilmente mal entendida para indicar tal causalidad.
Regresión:
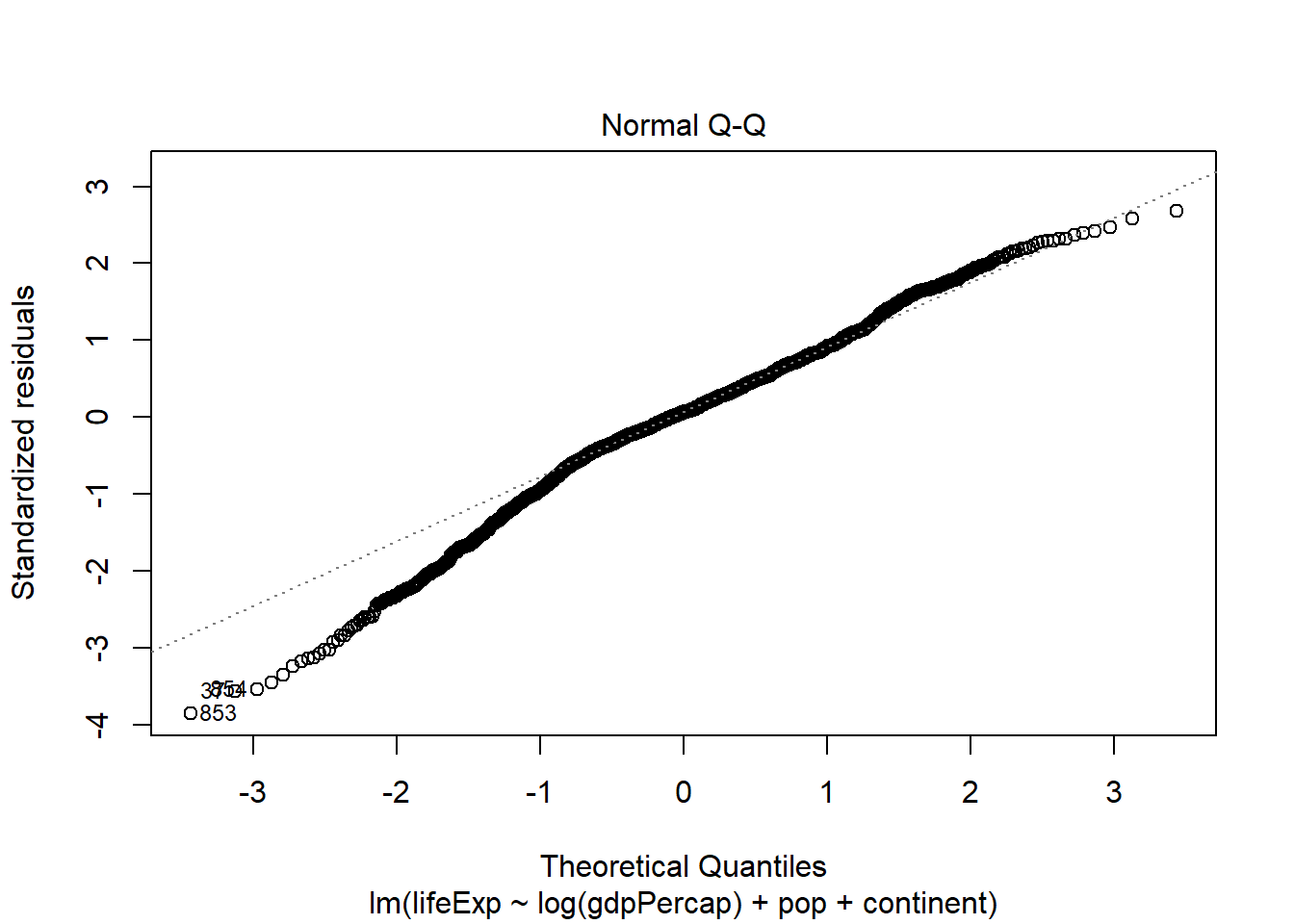
Modelización simple para conocer el R2, la valorización de parámetros y el comportamiento de errores de las variables utilizadas en el ejercicio, resultados que no afectarán las consideraciones anteriores pero permiten explorar un poco más la relación de los datos a través de un modelo li-log.Se utiliza la función Coefplot que permite una visualización gráfica de los coeficientes. Además, se incluyen los errores estándar del modelo ajustado.
##
## Call:
## lm(formula = lifeExp ~ log(gdpPercap) + pop + continent, data = gapminder)
##
## Residuals:
## Min 1Q Median 3Q Max
## -26.7090 -3.4832 0.4396 4.4062 18.6914
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.476e+00 1.352e+00 1.091 0.275
## log(gdpPercap) 6.524e+00 1.824e-01 35.778 < 2e-16 ***
## pop 9.990e-09 1.650e-09 6.056 1.72e-09 ***
## continentAmericas 6.729e+00 5.507e-01 12.218 < 2e-16 ***
## continentAsia 5.157e+00 4.880e-01 10.567 < 2e-16 ***
## continentEurope 9.290e+00 5.997e-01 15.491 < 2e-16 ***
## continentOceania 8.965e+00 1.521e+00 5.896 4.49e-09 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.965 on 1697 degrees of freedom
## Multiple R-squared: 0.7102, Adjusted R-squared: 0.7092
## F-statistic: 693.3 on 6 and 1697 DF, p-value: < 2.2e-16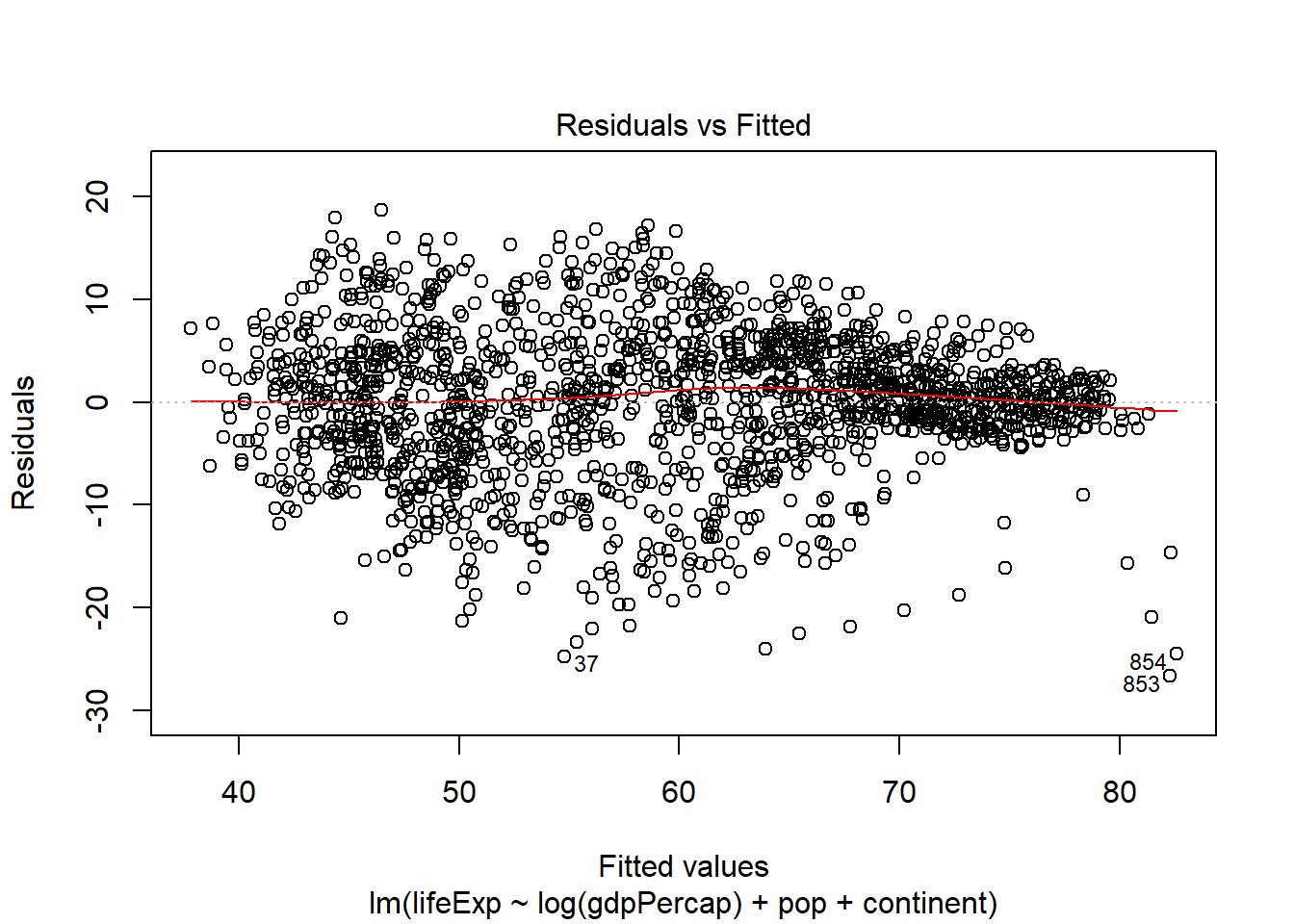
out <- lm(lifeExp ~ log(gdpPercap) + log(pop) + continent, data = gapminder)
coefplot(out, sort = "magnitude", intercept = FALSE)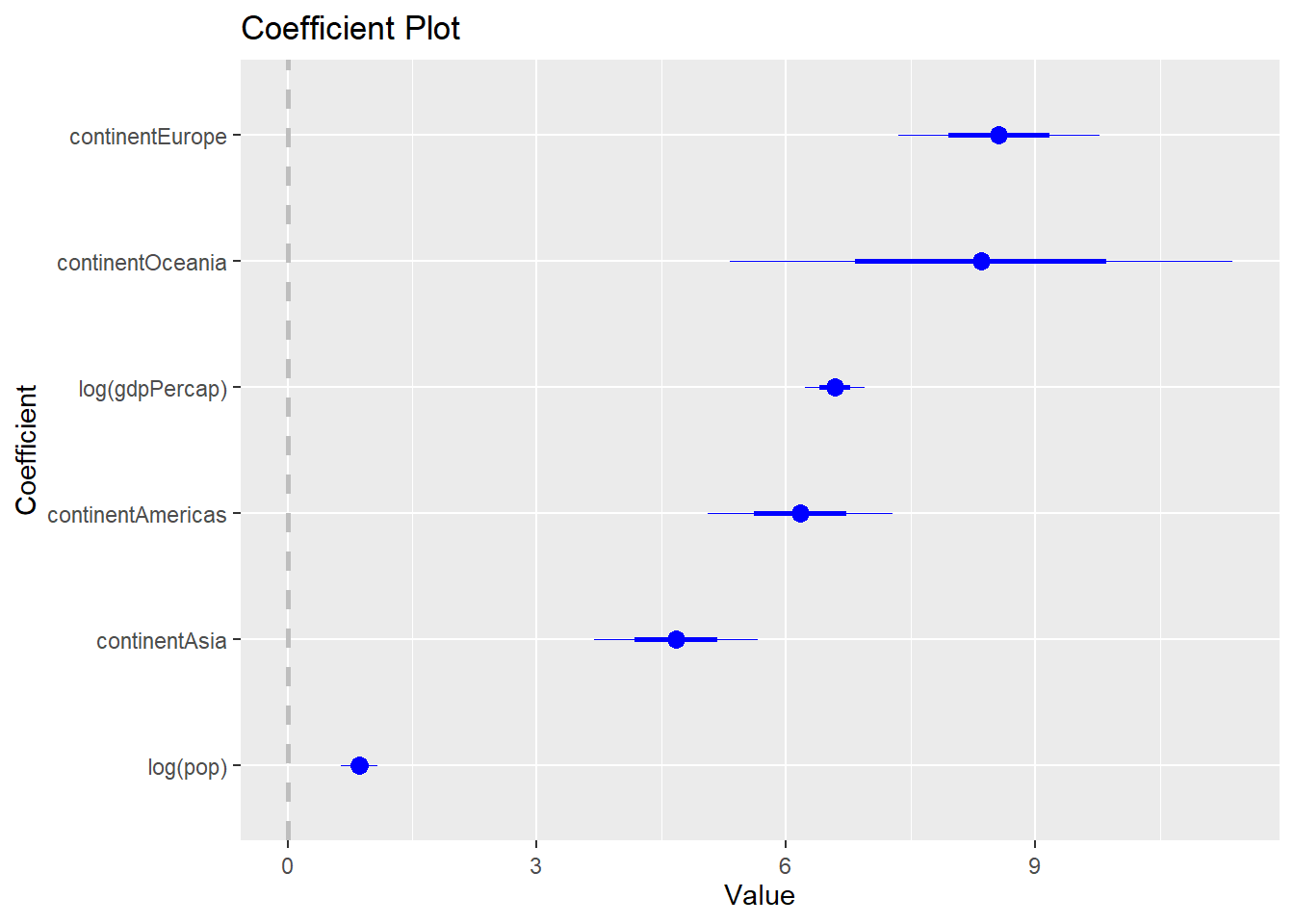
11. Exploración de datos Macroeconómicos
Se utilizará la fuente de datos macroeconómicos del Banco Mundial llamada Indicadores del desarrollo mundial (WDI) . El código Quandl para WDI es WWDI, y se antepone WWDI/ para cada llamada al conjunto de datos.
Comencemos con un ejemplo simple e importemos datos del PIB per cápita para Venezuela, cuyo código de país es VEN. Se puede solicitar el código ISO de cada país con la primera línea de código que se presenta, en el ejemplo son: Kenya, Venezuela, China.
Se utiliza el código WWDI/VEN _NY_GDP_PCAP_KN Quandl, que consiste en el código WDI WWDI/, agregando el código de país de Venezuela VEN, por último el código del PIB per cápita _NY_GDP_PCAP_KN.
gapminder %>%
filter(year == 2007, country %in% c("Kenya", "Venezuela", "China")) %>%
select(country, continent) %>%
left_join(country_codes)## # A tibble: 3 x 4
## country continent iso_alpha iso_num
## <chr> <fct> <chr> <int>
## 1 China Asia CHN 156
## 2 Kenya Africa KEN 404
## 3 Venezuela Americas VEN 862Venezuela_GDPPC <- Quandl("WWDI/VEN_NY_GDP_PCAP_KN", type = 'xts') %>%
`colnames<-`("PIB Per Capita")
tail(Venezuela_GDPPC, n = 20)## PIB Per Capita
## 1999-12-31 1666.183
## 2000-12-31 1695.293
## 2001-12-31 1720.546
## 2002-12-31 1539.820
## 2003-12-31 1395.319
## 2004-12-31 1622.226
## 2005-12-31 1760.096
## 2006-12-31 1903.768
## 2007-12-31 2040.218
## 2008-12-31 2117.724
## 2009-12-31 2021.009
## 2010-12-31 1962.294
## 2011-12-31 2012.515
## 2012-12-31 2091.416
## 2013-12-31 2089.537
## 2014-12-31 1990.680
## 2015-12-31 1864.555
## 2016-12-31 1559.042
## 2017-12-31 1335.106
## 2018-12-31 1092.476Extracción de Variables Macroeconómicas de la base de datos del Banco Mundial
Se seleccionan las variables macro que se observarán en el ejercicio en total son ocho (8): PIB per Cápita, crecimiento del PIB per Cápita, Tasa de Interés Real, Tipo de Cambio, Índice Nacional de Precios al Consumidor, Fuerza Laboral, Formación Bruta de Capital y por última Importación de Bienes y Servicios.
En los detalles, se usará la función reduce() del paquete purrr y se aplicará merge() para combinar las ocho listas de un objeto xts. La visualización se realizará con dygraphs. La última función colnames<- se usa para limpiar los nombres de columna.
econIndicators <- c("PIB Per Capita" = "WWDI/VEN_NY_GDP_PCAP_KN",
"Crecimiento PIB Per Capita" = "WWDI/VEN_NY_GDP_PCAP_KD_ZG",
"Tasa de Interés Real" = "WWDI/VEN_FR_INR_RINR",
"Tipo de Cambio" = "WWDI/VEN_PX_REX_REER",
"INPC" = "WWDI/VEN_FP_CPI_TOTL_ZG",
"Parte de la Fuerza Laboral. Rate" = "WWDI/VEN_SL_TLF_ACTI_ZS","Formación Bruta de Capital" = "WWDI/VEN_NE_GDI_TOTL_ZS","Importación de Bienes y Servicios" = "WWDI/VEN_NE_IMP_GNFS_ZS")
Quandl.api_key("d9EidiiDWoFESfdk5nPy")
Venezuela_all_indicators <-
econIndicators %>%
map(Quandl, type = "xts") %>%
reduce(merge) %>%
`colnames<-`(names(econIndicators))
tail(Venezuela_all_indicators, n = 6)## PIB Per Capita Crecimiento PIB Per Capita Tasa de Interés Real
## 2014-12-31 1990.680 -4.731050 -16.53998
## 2015-12-31 1864.555 -6.335766 -57.77085
## 2016-12-31 1559.042 -16.385328 -71.33319
## 2017-12-31 1335.106 -14.363688 -85.72509
## 2018-12-31 1092.476 -18.173106 NA
## 2019-12-31 NA NA NA
## Tipo de Cambio INPC Parte de la Fuerza Laboral. Rate
## 2014-12-31 128.9562 62.16865 66.675
## 2015-12-31 310.0486 121.73809 66.550
## 2016-12-31 740.6139 254.94853 65.949
## 2017-12-31 2321.5493 NA 65.346
## 2018-12-31 NA NA 64.499
## 2019-12-31 NA NA 64.301
## Formación Bruta de Capital Importación de Bienes y Servicios
## 2014-12-31 24.8102028 31.39699
## 2015-12-31 30.8684616 63.00163
## 2016-12-31 0.1023607 27.29002
## 2017-12-31 -3.7436802 36.43282
## 2018-12-31 NA NA
## 2019-12-31 NA NA
Luego de seleccionar las variables de interés se verifican las fechas disponibles, es decir la fecha de inicio y final, esto se puede observar cuando se grafiquen.
Luego de revisar los datos se utilizará la función de gráficos dygraph() para visualizar las series de tiempo y asegurarse que están todas correctas. En la página del Banco Mundial se pueden conocer las rutas de cada variable para luego cargarlas desde R.
dygraph(Venezuela_all_indicators$`PIB Per Capita`, main = "PIB Per Capita en Venezuela (US $ a precios actuales)")%>%
dyRangeSelectordygraph(Venezuela_all_indicators$`Crecimiento PIB Per Capita`, main = "Crecimiento PIB Per Capita en Venezuela (% anual)")%>%
dyRangeSelectordygraph(Venezuela_all_indicators$`Tasa de Interés Real`, main = "Tasa de Interés Real en Venezuela (%)")%>%
dyRangeSelectordygraph(Venezuela_all_indicators$`Tipo de Cambio`, main = "Tipo de Cambio en Venezuela (VEF / US $)")%>%
dyRangeSelectordygraph(Venezuela_all_indicators$`INPC`, main = "INPC en Venezuela (2010 = 100)")%>%
dyRangeSelectordygraph(Venezuela_all_indicators$`Parte de la Fuerza Laboral. Rate`, main = "Parte de la Fuerza Laboral en Venezuela")%>%
dyRangeSelectordygraph(Venezuela_all_indicators$`Formación Bruta de Capital`, main = "Formación Bruta de Capital en Venezuela (% de crecimiento anual)")%>%
dyRangeSelectordygraph(Venezuela_all_indicators$`Importación de Bienes y Servicios`, main = "Importación de Bienes y Servicios en Venezuela (%) del PIB")%>%
dyRangeSelector
En el caso de Venezuela el año del desplome de su economía se aceleró en el 2015. Logrando nuevos records de mínimos históricos en casi todas sus variables macroeconómicas que indican prosperidad, bienestar y desarrollo. Y nuevos máximos históricos en las que indican pobreza, miseria, desigualdad, corrupción y subdesarrollo. No es el fin del entrenamiento profundizar en el tema. Sin embargo, se puede comenzar un análisis más completo utilizando la data no solo del Banco Mundial, sino de otros organismos internacionales.
12. Construcción del Mapa para Estadística Espacial
Se utilizará el paquete rnaturalearth y su función ne_countries(). Vamos a especificar type = “countries” y returnclass = ‘sf’. Se puede configurar returnclass = ‘sp’ si quisiéramos trabajar con un marco de datos espaciales, pero para comenzar con este tema el sf y el marco de datos de características simples sirve para proyectos de mapeo.
world <- ne_countries(type = "countries", returnclass = 'sf')
tail(world[c('name', 'pop_est','gdp_md_est', 'economy','income_grp')], n = 10)## Simple feature collection with 10 features and 5 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -171.7911 ymin: -34.95265 xmax: 167.8449 ymax: 71.35776
## CRS: +proj=longlat +datum=WGS84 +no_defs +ellps=WGS84 +towgs84=0,0,0
## name pop_est gdp_md_est economy
## 167 Uruguay 3494382 43160.0 5. Emerging region: G20
## 168 United States 313973000 15094000.0 1. Developed region: G7
## 169 Uzbekistan 27606007 71670.0 6. Developing region
## 170 Venezuela 26814843 357400.0 5. Emerging region: G20
## 171 Vietnam 86967524 241700.0 5. Emerging region: G20
## 172 Vanuatu 218519 988.5 7. Least developed region
## 173 Yemen 23822783 55280.0 7. Least developed region
## 174 South Africa 49052489 491000.0 5. Emerging region: G20
## 175 Zambia 11862740 17500.0 7. Least developed region
## 176 Zimbabwe 12619600 9323.0 5. Emerging region: G20
## income_grp geometry
## 167 3. Upper middle income MULTIPOLYGON (((-57.62513 -...
## 168 1. High income: OECD MULTIPOLYGON (((-155.5421 1...
## 169 4. Lower middle income MULTIPOLYGON (((66.51861 37...
## 170 3. Upper middle income MULTIPOLYGON (((-71.33158 1...
## 171 4. Lower middle income MULTIPOLYGON (((108.0502 21...
## 172 4. Lower middle income MULTIPOLYGON (((167.8449 -1...
## 173 4. Lower middle income MULTIPOLYGON (((53.10857 16...
## 174 3. Upper middle income MULTIPOLYGON (((31.521 -29....
## 175 4. Lower middle income MULTIPOLYGON (((32.75938 -9...
## 176 5. Low income MULTIPOLYGON (((31.19141 -2...
En particular, observemos la columna geometry, que contiene las coordenadas de latitud y longitud multipolígono. El objeto sf parece más intuitivo en términos de cómo la geometría se corresponde con el resto de los datos. Ahora se creará el sombreado y ventanas emergentes.
popup <- paste0("<strong>Country: </strong>",
world$name,
"<br><strong>Market Stage: </strong>",
world$income_grp)
Por último se construye el mapa. Necesitamos pasar un código de país a Quandl, no el nombre del país ni su símbolo de teletipo. Por lo tanto, no queremos establecer layerId = name, tampoco necesitamos agregar nada especial a nuestro objeto world. Ya contiene una columna llamada iso_a3, y esa columna contiene los códigos de país utilizados por Quandl.
leaf_world <- leaflet(world) %>%
addProviderTiles("CartoDB.Positron") %>%
setView(lng = 20, lat = 15, zoom = 2) %>%
addPolygons(stroke = FALSE, smoothFactor = 0.2, fillOpacity = .7,
color = ~gdpPal(gdp_md_est), layerId = ~iso_a3, popup = popup)
leaf_world
Debido a que Quandl usa el código ISO de 3 letras para identificar un país, y porque el rnaturalearth objeto sf ya contiene una columna con códigos de país iso_a3. Ahora, tenemos un mapa con layerID = iso_a3 la columna incorporada de códigos de país.
Las degradaciones del color indican los países con mayor o menor concentración de PIB per Cápita y al hacer clic en algún país se muestran algunos datos económicos.
Puedes compartir este material:
Por:
Jesús Benjamín Zerpa
Economista
JesusZerpaEconomia@Gmail.Com
 Excepto donde se indique lo contrario, el contenido de esta obra está bajo una licencia de Creative Commons Reconocimiento 4.0 Internacional.
Excepto donde se indique lo contrario, el contenido de esta obra está bajo una licencia de Creative Commons Reconocimiento 4.0 Internacional.
| FINANCE | INTELLIGENCE BUSSINES | FORECASTING | TIME SERIES | FINANCIAL DASHBOARD | FINANCIAL BUDGET | SPATIAL ECONOMETRICS |
| FINANCE | INTELLIGENCE BUSSINES | FORECASTING | TIME SERIES | FINANCIAL DASHBOARD | FINANCIAL BUDGET | SPATIAL ECONOMETRICS |