Análisis de procesos comerciales con Rstudio -Data Mining-

Contenido
1. ¿Qué es la minería de datos?
2. Aplicaciones del data mining
3. Análisis de procesos de negocio
4. Paqueterías
5. Creación de un Event-log
6. ¿Qué es un Data Frame?
7. Objeto de registro de eventos
8. Análisis de datos exploratorios
9. Frecuencia de actividades
10. Construcción de mapas de procesos
11. Perfil de frecuencia
12. Perfil de rendimiento
13. Perfil personalizado
14. Animación del mapa de procesos
15. Gráficos de puntos
16. Referencias
2. Aplicaciones del data mining
3. Análisis de procesos de negocio
4. Paqueterías
5. Creación de un Event-log
6. ¿Qué es un Data Frame?
7. Objeto de registro de eventos
8. Análisis de datos exploratorios
9. Frecuencia de actividades
10. Construcción de mapas de procesos
11. Perfil de frecuencia
12. Perfil de rendimiento
13. Perfil personalizado
14. Animación del mapa de procesos
15. Gráficos de puntos
16. Referencias
1. ¿Qué es la minería de datos?
La minería de datos, también conocida como Knowledge Discovery in Data (KDD), es una herramienta prometedora que ayuda a descubrir conocimiento valioso oculto, encontrar patrones, correlaciones dentro de grandes conjuntos de datos y relaciones dentro de sus datos.
La Ciencia de Datos es multidisciplinaria. Es como un paraguas y la minería de datos es uno de sus componentes. Se pueden reconocer y calificar Patrones con Data Mining, que no se pudieron determinar antes. La minería de datos es una tecnología relativamente nueva que analiza grandes cantidades de datos y tendencias almacenadas en bases de datos o depósitos de datos , con lo que anteriormente no se podía ir más allá del simple análisis.
2. Aplicaciones del Data Mining
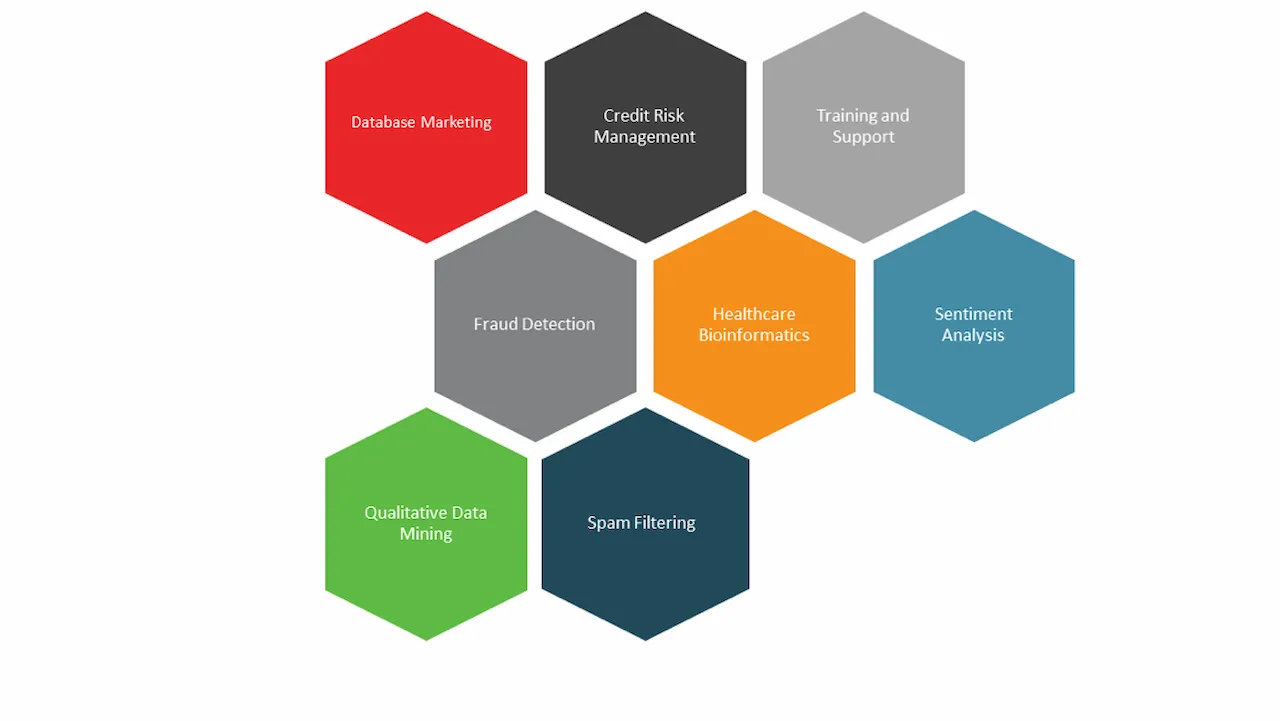
Marketing de base de datos y orientación
Los minoristas utilizan la minería de datos para comprender mejor a sus clientes. La minería de datos les permite segmentar mejor los grupos de mercado y personalizar las promociones para profundizar y ofrecer promociones personalizadas a diferentes consumidores.
Gestión del riesgo del crédito y calificación crediticia
Los bancos implementan modelos de minería de datos para predecir la capacidad del prestatario de asumir y pagar deudas. Utilizando una variedad de información demográfica y personal, estos modelos seleccionan automáticamente una tasa de interés basada en el nivel de riesgo asignado al cliente. Los solicitantes con mejores puntajes de crédito generalmente reciben tasas de interés más bajas ya que el modelo usa este puntaje como un factor en su evaluación.
Detección y Prevención de Fraudes
Las instituciones financieras implementan modelos de minería de datos para detectar y detener automáticamente las transacciones fraudulentas. Esta forma de informática forense ocurre detrás de escena con cada transacción y, a veces, sin que el consumidor lo sepa. Al rastrear los hábitos de gasto, estos modelos marcarán transacciones aberrantes y retendrán pagos instantáneamente hasta que los clientes verifiquen la compra. Los algoritmos de minería de datos pueden funcionar de forma autónoma para proteger a los consumidores de transacciones fraudulentas a través de un correo electrónico o una notificación de texto para confirmar una compra.
Bioinformática Sanitaria
Los profesionales de la salud utilizan modelos estadísticos para predecir la probabilidad de un paciente de diferentes afecciones de salud en función de los factores de riesgo. Los datos demográficos, familiares y genéticos pueden modelarse para ayudar a los pacientes a realizar cambios para prevenir o mediar la aparición de condiciones de salud negativas. Estos modelos se implementaron recientemente en países en desarrollo para ayudar a diagnosticar y priorizar a los pacientes antes de que los médicos llegaran al sitio para administrar el tratamiento.
Filtrado de Spam
La minería de datos también se usa para combatir la afluencia de correo electrónico no deseado y malware. Los sistemas pueden analizar las características comunes de millones de mensajes maliciosos para informar el desarrollo de software de seguridad. Más allá de la detección, este software especializado puede ir un paso más allá y eliminar estos mensajes incluso antes de que lleguen a la bandeja de entrada del usuario.
Sistemas de recomendación
Los sistemas de recomendación ahora se usan ampliamente entre los minoristas en línea. El modelo predictivo de comportamiento del consumidor es ahora un foco central de muchas organizaciones y se considera esencial para competir. Empresas como Amazon y Macy’s crearon sus propios modelos de minería de datos patentados para pronosticar la demanda y mejorar la experiencia del cliente en todos los puntos de contacto. Netflix ofreció un premio de un millón de dólares por un algoritmo que aumentaría significativamente la precisión de su sistema de recomendación. El modelo ganador mejoró la precisión de las recomendaciones en más del 8%.
Análisis de los sentimientos
El análisis de sentimientos de los datos de las redes sociales es una aplicación común de minería de datos que utiliza una técnica llamada minería de texto. Este es un método utilizado para comprender cómo se siente un grupo agregado de personas con respecto a un tema. La minería de texto implica el uso de una entrada de los canales de redes sociales u otra forma de contenido público para obtener información clave como resultado del reconocimiento de patrones estadísticos. Un paso más allá, las técnicas de procesamiento del lenguaje natural (PNL) se pueden utilizar para encontrar el significado contextual detrás del lenguaje humano utilizado.
Minería de datos cualitativa
La investigación cualitativa puede estructurarse y luego analizarse utilizando técnicas de minería de texto para dar sentido a grandes conjuntos de datos no estructurados. Investigadores de Berkley publicaron una mirada en profundidad sobre cómo se ha utilizado esto para estudiar el bienestar infantil.
Minería de Datos en el conjunto de procesos de Inteligencia de Negocios (BI)
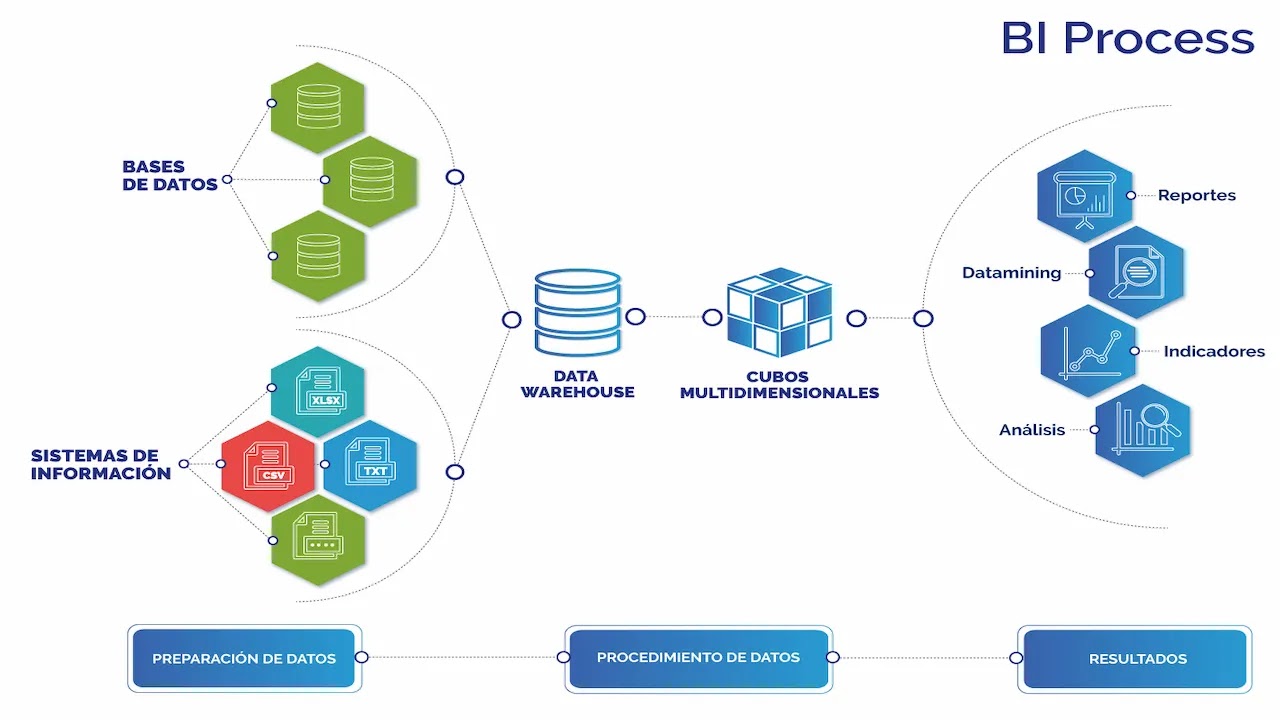
Hoy en día las organizaciones almacenan o manejan grandes cantidades de datos provenientes de distintas áreas del negocio, dichos datos están relacionados con diversos procesos comerciales. La minería de datos permite optimizar esos procesos mediante el análisis y la aplicación de técnicas. Las empresas que desarrollan esta área les permitirá tener una ventaja competitiva. La minería de procesos se inició con el descubrimiento de modelos de flujo de trabajo a partir de datos de eventos. Sin embargo, durante los últimos 20 años, el campo de la minería de datos se ha convertido en una disciplina de investigación amplia y diversa.
Para la plataforma de Rstudio un grupo de investigación de Business Informatics de la Universidad Hasselt, Bélgica, desarrolló un interesante paquete en código abierto denominado bupaR. El paquete central incluye una funcionalidad básica para crear objetos de registro de eventos en R.
Contiene varias funciones para obtener información sobre un registro de eventos y también proporciona versiones de registro de eventos específicos de funciones genéricas en R. Junto con los paquetes relacionados, cada uno de los cuales tiene su propio propósito específico, bupaR tiene como objetivo apoyar cada paso en el análisis de datos de eventos con R, desde la importación de datos hasta el monitoreo de procesos en línea. Aquí puedes visualizar todo lo que hace el paquete.
Descripción: En el siguiente entrenamiento utilizaré las principales funciones del paquete bupaR para conocer el potencial y alcance de su contenido en ser aplicado al Anaysis Business, Data Analytics y Data Mining. Igualmente utilizaré otros paquetes que ayudaran a realizar el análisis completo añadiendo otras características. En el ejemplo se utilizan los datos de pacientes de un centro de salud privada.
4. Paqueterías
bupaR: Conjunto de herramientas completo de análisis de procesos de negocio. Crea la clase S3 para objetos de registro de eventos y funciones de controlador relacionadas. Importa paquetes relacionados para el filtrado de datos de eventos, cálculo de estadísticas descriptivas, manejo de objetos ‘Petri Net’ y visualización de mapas de procesos. Consulte también los paquetes ‘edeaR’, ‘processmapR’, ‘eventdataR’ y ‘processmonitR’.
eventdataR: Repositorio de conjuntos de datos de eventos que incluye registros de eventos tanto de la vida real como artificiales. Se pueden usar en combinación con las funcionalidades proporcionadas por los paquetes ‘bupaR’ ‘edeaR’, ‘processmapR’, etc.
processanimateR: Proporciona mapas de procesos animados basados en el paquete ‘procesmapR’. Los casos almacenados en registros de eventos creados con el registro de eventos de clase S3 ‘bupaR’ son renderizados como tokens (formas SVG) y animados según su ocurrencia veces en la parte superior del mapa de procesos. Para renderizar animaciones SVG (‘SMIL’) se utiliza el paquete ‘htmlwidget’.
5. Creación de un Event-log
Esta función necesita como argumentos un data.frame y los nombres de columna de los campos apropiados que describen el identificador de caso, identificador de actividad, marca de tiempo, transición del ciclo de vida, recurso e identificador de instancia de actividad. Se puede crear un registro de eventos con requisitos mínimos (marca de tiempo, caso e identificador de actividad) con la función simple_eventlog. Ambas funciones tienen una alternativa, prefijada con la letra i de interfaz, para configurar los identificadores con una GUI. En ese caso, solo se deben proporcionar los datos como argumento.
6. ¿Qué es un Data Frame?
Es una tabla o una estructura bidimensional similar a una matriz en la que cada columna contiene valores de una variable y cada fila contiene un conjunto de valores de cada columna.
A continuación se muestran las características de un data frame:
- Los nombres de las columnas no deben estar vacíos.
- Los nombres de las filas deben ser únicos.
- Los datos almacenados en un marco de datos pueden ser de tipo numérico, factorial o de carácter.
- Cada columna debe contener el mismo número de elementos de datos.
La función data.frame() crea marcos de datos, colecciones de variables estrechamente acopladas que comparten muchas de las propiedades de las matrices y de las listas, utilizadas como la estructura de datos fundamental por la mayoría del software de modelado de R.
t=Sys.time()
data <- data.frame(case = rep("A",5),
activity_id = c("A","B","C","D","E"),
activity_instance_id = 1:5,
lifecycle_id = rep("complete",5),
timestamp = c(t,t+1000,t+2000,t+3000,t+4000),
resource = rep("resource 1", 5))
data## case activity_id activity_instance_id lifecycle_id timestamp
## 1 A A 1 complete 2020-08-08 15:01:56
## 2 A B 2 complete 2020-08-08 15:18:36
## 3 A C 3 complete 2020-08-08 15:35:16
## 4 A D 4 complete 2020-08-08 15:51:56
## 5 A E 5 complete 2020-08-08 16:08:36
## resource
## 1 resource 1
## 2 resource 1
## 3 resource 1
## 4 resource 1
## 5 resource 1## [1] "data.frame"7. Objeto de registro de eventos
Así se crea el objeto de registro de eventos con la función eventlog():
primer_log <- bupaR::eventlog(data,case_id = "case",
activity_id = "activity_id",
activity_instance_id = "activity_instance_id",
lifecycle_id = "lifecycle_id",
timestamp = "timestamp",
resource_id = "resource")
activity_presence(primer_log)## # A tibble: 5 x 3
## activity_id absolute relative
## <fct> <int> <dbl>
## 1 A 1 1
## 2 B 1 1
## 3 C 1 1
## 4 D 1 1
## 5 E 1 1## [1] "eventlog" "tbl_df" "tbl" "data.frame"8. Análisis de datos exploratorio y descriptivo basado en eventos
## [1] "eventlog" "tbl_df" "tbl" "data.frame"
Después de preparar los datos y crear un objeto de registro de eventos, podemos usar algunas funciones del paquete para obtener información básica del registro, así como metadatos. Utilizaremos el comando “Head” para conocer los primeros datos.
## Log of 6 events consisting of:
## 1 trace
## 6 cases
## 6 instances of 1 activity
## 1 resource
## Events occurred from 2017-01-02 11:41:53 until 2017-01-04 16:07:47
##
## Variables were mapped as follows:
## Case identifier: patient
## Activity identifier: handling
## Resource identifier: employee
## Activity instance identifier: handling_id
## Timestamp: time
## Lifecycle transition: registration_type
##
## # A tibble: 6 x 7
## handling patient employee handling_id registration_ty~ time
## <fct> <chr> <fct> <chr> <fct> <dttm>
## 1 Registr~ 1 r1 1 start 2017-01-02 11:41:53
## 2 Registr~ 2 r1 2 start 2017-01-02 11:41:53
## 3 Registr~ 3 r1 3 start 2017-01-04 01:34:05
## 4 Registr~ 4 r1 4 start 2017-01-04 01:34:04
## 5 Registr~ 5 r1 5 start 2017-01-04 16:07:47
## 6 Registr~ 6 r1 6 start 2017-01-04 16:07:47
## # ... with 1 more variable: .order <int>## # A tibble: 7 x 3
## handling absolute relative
## <fct> <int> <dbl>
## 1 Registration 500 1
## 2 Triage and Assessment 500 1
## 3 Discuss Results 495 0.99
## 4 Check-out 492 0.984
## 5 X-Ray 261 0.522
## 6 Blood test 237 0.474
## 7 MRI SCAN 236 0.472
Podemos ver un resumen general del registro de eventos llamando a la función “summary”.
## Number of events: 5442
## Number of cases: 500
## Number of traces: 7
## Number of distinct activities: 7
## Average trace length: 10.884
##
## Start eventlog: 2017-01-02 11:41:53
## End eventlog: 2018-05-05 07:16:02## handling patient employee handling_id
## Blood test : 474 Length:5442 r1:1000 Length:5442
## Check-out : 984 Class :character r2:1000 Class :character
## Discuss Results : 990 Mode :character r3: 474 Mode :character
## MRI SCAN : 472 r4: 472
## Registration :1000 r5: 522
## Triage and Assessment:1000 r6: 990
## X-Ray : 522 r7: 984
## registration_type time .order
## complete:2721 Min. :2017-01-02 11:41:53 Min. : 1
## start :2721 1st Qu.:2017-05-06 17:15:18 1st Qu.:1361
## Median :2017-09-08 04:16:50 Median :2722
## Mean :2017-09-02 20:52:34 Mean :2722
## 3rd Qu.:2017-12-22 15:44:11 3rd Qu.:4082
## Max. :2018-05-05 07:16:02 Max. :5442
## 9. Frecuencias de actividades
A continuación se realizarán llamados para obtener información de las frecuencias absolutas y relativas.

## # A tibble: 16 x 3
## activity absolute relative
## <fct> <int> <dbl>
## 1 ER Registration 1050 1
## 2 ER Triage 1050 1
## 3 ER Sepsis Triage 1049 0.999
## 4 Leucocytes 1012 0.964
## 5 CRP 1007 0.959
## 6 LacticAcid 860 0.819
## 7 IV Antibiotics 823 0.784
## 8 Admission NC 800 0.762
## 9 IV Liquid 753 0.717
## 10 Release A 671 0.639
## 11 Return ER 294 0.28
## 12 Admission IC 110 0.105
## 13 Release B 56 0.0533
## 14 Release C 25 0.0238
## 15 Release D 24 0.0229
## 16 Release E 6 0.00571
10. Construcción de Mapa de Procesos
La función “process_map” se encarga de diseñar y elaborar un mapa de procesos de un registro de eventos. En el paquete, se puede encontrar un ejemplo de un mapa de proceso para el registro de eventos de los pacientes.
11. Perfil de frecuencia
De forma predeterminada, el mapa de procesos está anotado con frecuencias de actividades y flujos. Es lo que se llama perfil de frecuencia y se puede crear explícitamente utilizando la función “frequency”. Esta función tiene un “argumento de valor”, que puede usarse para ajustar las frecuencias mostradas, por ejemplo, usando frecuencias relativas en lugar de las absolutas predeterminadas.
12. Perfil de rendimiento
En lugar de un perfil de frecuencia, también se puede utilizar un perfil de desempeño, centrándose en el tiempo de procesamiento de las actividades. El perfil de rendimiento tiene dos argumentos: el argumento FUN para especificar la función que se aplicará en el tiempo de procesamiento (p. Ej., Mínimo, máximo, media aritmética, mediana, etc.) y el argumento de las unidades para especificar la unidad de tiempo que se utilizará.
13. Perfil personalizado
Junto a los perfiles específicos anteriores, también se pueden proyectar atributos numéricos personalizados. Esto se puede lograr con el comando “custom”. Requiere una función de agregación (media, mediana, suma, mínima, etc.) y un atributo numérico. El argumento de las unidades se puede utilizar para indicar cómo se deben interpretar los valores (por ejemplo, “USD” para valores monetarios). Para las aristas, mostrará los valores relacionados con la actividad saliente.
Combinando diferentes perfiles
El perfil utilizado para los bordes y los nodos se puede diferenciar mediante los atributos “type_edges” y en “type_nodes” lugar del argumento “type”. De esta forma, la información sobre frecuencias y rendimiento, o cualquier otro valor, se puede combinar en un mismo gráfico.
14. Animación del Mapa de Procesos
Se puede observar una animación de los mapas de procesos, simplemente mueve el deslizante hacia el comienzo del gráfico.
animate_process(patients, mode = "relative", jitter = 10, legend = "color",
mapping = token_aes(color = token_scale("employee",
scale = "ordinal",
range = RColorBrewer::brewer.pal(7, "Paired"))))15. Gráficos de puntos
Se pueden hacer gráficos de puntos con la función “dotted_chart”. Un gráfico de puntos es un gráfico en el que cada instancia de actividad se muestra con un punto. El eje “x” se refiere al aspecto del tiempo, mientras que el eje “y” se refiere a casos. La función de gráfico de puntos tiene 3 argumentos
- x: ya sea absoluto (tiempo absoluto en el eje x) o relativo (diferencia de tiempo desde el caso de inicio en el eje x)
- y: el orden de los casos a lo largo del eje y: por inicio, finalización o duración.
- color: el atributo utilizado para colorear las instancias de actividad. Por defecto al tipo de actividad.
El gráfico de puntos es un gráfico similar a un gráfico de Gannt. Muestra una distribución de eventos de un registro de eventos a lo largo del tiempo. La idea básica del gráfico de puntos es trazar puntos de acuerdo con el tiempo.


16. Referencias:
Janssenswillen, G., Depaire, B., Swennen, M., Jans, M. y Vanhoof, K. (2019). bupaR: Habilitación de análisis de procesos comerciales reproducibles. Sistemas basados en el conocimiento, 163, 927-930.
Puedes compartir este material:
Por:
Jesús Benjamín Zerpa
Economista
JesusZerpaEconomia@Gmail.Com
 Excepto donde se indique lo contrario, el contenido de esta obra está bajo una licencia de Creative Commons Reconocimiento 4.0 Internacional.
Excepto donde se indique lo contrario, el contenido de esta obra está bajo una licencia de Creative Commons Reconocimiento 4.0 Internacional.
| FINANCE | INTELLIGENCE BUSSINES | FORECASTING | TIME SERIES | FINANCIAL DASHBOARD | FINANCIAL BUDGET | SPATIAL ECONOMETRICS |
| FINANCE | INTELLIGENCE BUSSINES | FORECASTING | TIME SERIES | FINANCIAL DASHBOARD | FINANCIAL BUDGET | SPATIAL ECONOMETRICS |